Tools
.




The goal of sprint planning is to deliver realistic forecasts. However, research shows that most agile teams commit 20–40% more work than their capacity allows. When your team starts more work than they can finish, context switching increases, work‑in‑progress grows, and quality suffers. In this article, we’ll discuss the reasons why even talented teams overcommit during sprint planning, the costs of overestimating capacity, and practical steps that will help you stop overcommitting in your sprints.
What’s The Cost of Overestimating Capacity?
1. Delivery Delays and Technical Debt: Overcommitting work almost always comes at a cost. When your team takes on more than they can realistically deliver, schedules slip, and quality suffers. To keep pace, your engineers will resort to quick fixes and workarounds. These shortcuts may fix the issue temporary but will accumulate as technical debt, slowing future development, increasing defect rates, and making the product harder to maintain.
As Martin Fowler explains, technical debt behaves like financial debt: “the extra effort that it takes to add new features is the interest paid on the debt.”
In many cases, what begins as a deliberate shortcut (to hit a date) escalates into reckless debt when left unmanaged.
2. Pressure and Burnout: Optimism bias and external pressure may push you to dismiss breaks, holidays, and support demands. You believe that “we’ll make it up later. Research shows developers spend only about 16% of their time coding; the rest is devoted to requirements, testing, CI/CD, and ongoing support tasks.
When additional, unrealistic commitments are added to this workload, you miss your deadlines, quality declines, and pressure increases. Optimism bias may help you start with confidence, but over time, it erodes trust, morale, and retention. High-performing engineers in particular are quick to recognize when an environment is unsustainable and are just as quick to seek one that respects capacity and balance.
3. Gaming the system. When a team faces intense delivery pressure, they may subtly reshape their metrics rather than their outcomes. Mid-sprint, they may add extra stories or re-estimate unfinished work to make burndown charts look smoother. These actions may help the dashboard look good, but it hide the true state of things.
This is a classic illustration of Goodhart’s Law: “When a measure becomes a target, it ceases to be a good measure.” Once metrics become goals themselves, the behaviors around them change, often in ways that sabotage the original intent.
Incentives, even seemingly innocent ones, become targets for gaming. In the agile context, for example, velocity is volatile and frequently manipulated (“cooking the agile books”) when used as a performance target.
4. Quality bottlenecks: When you defer large batches of work until late in a sprint, you stack testing and validation into the final days. What happens is, QA becomes overwhelmed, defects slip by, and stories roll over.
Some carryover is normal, especially if it still serves the sprint goal. But when spillover becomes habitual and disconnected from your goal, it shows flaws in planning and execution.
Persistent spillover also happens when your team avoids working incrementally or defers complexity until late in the sprint. You might even move functional testing earlier, but if areas like performance, security, and scalability are still tested last, you’d create QA bottlenecks that undermine delivery flow.
What Causes of Sprint Planning Overcommitment?
1. Psychological safety gaps and cultural pressure: In many organizations, developers feel unsafe questioning the plan or pushing back against unrealistic scope. When you place more value on point totals than on business outcomes, you’re signaling to your team that you reward compliance over candor.
They quickly learn to inflate estimates or commit to low-value work, not because it drives impact, but because it satisfies the metric. The result of this is a distorted picture of progress that undermines trust and long-term performance.
2. Estimation blind spots: Many teams base their estimates on past velocity without adjusting for the realities of time away, meetings, or unplanned support. On paper, a five-person team working 40-hour weeks looks like 200 hours of capacity. In practice, once you deduct meetings, code reviews, context switching, and other overhead, the team may have closer to 100 hours of true focus time — barely half of what was assumed.
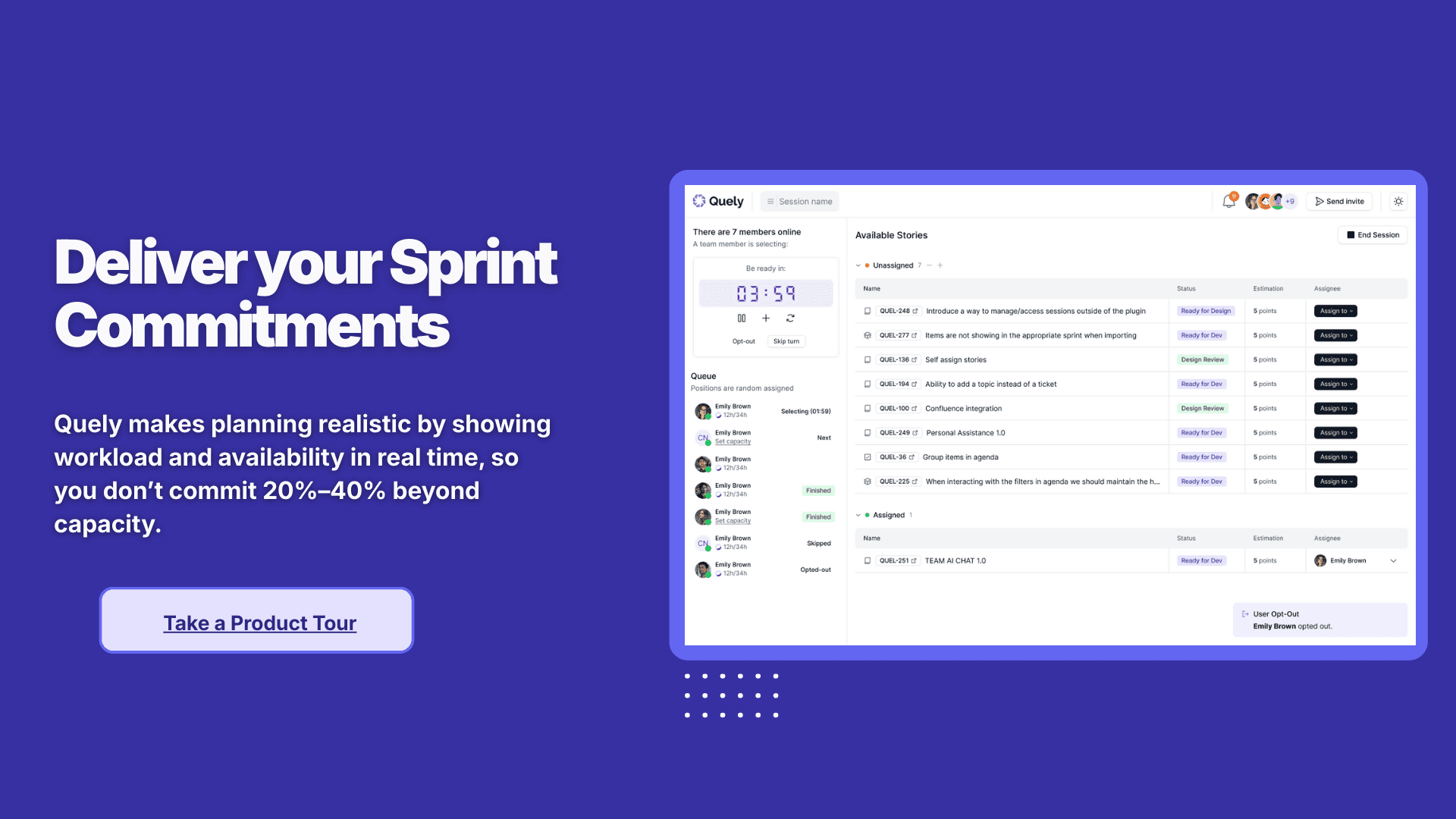
Without a structured way to account for these factors, like using Quely’s capacity planning feature, these gaps remain invisible in planning. The result is overcommitment, missed expectations, and repeated cycle strain that could have been avoided with more realistic modeling.
As Mike Cohn explains, velocity is a useful trend indicator but not a substitute for capacity planning. Effective sprint planning requires adjusting for the actual time available each iteration, not just projecting from past averages. Without capacity planning tools like Quely, these variances remain hidden, and you will continue to overcommit
3. Misuse of Metrics: Metrics can quickly lose meaning when they shift from guiding improvement to staging performance. Burndown charts and story-point totals, for example, become performative if your team games the numbers. If your team has ever asked the question “Is it okay to add stories mid-sprint so our burndown looks better?”, it shows that you have a culture that values optics over outcomes.
When numbers become the focus, learning and delivery take a back seat. What you’re left with are dashboards that distort reality instead of improving it. If you accept these numbers at face value, you’d be misled by agile theatre instead of delivery.
How to Stop Carrying Stories Over Every Sprint
1. Anchor Every Sprint to a Clear Goal: A sprint backlog is a forecast, not a contract. The real commitment is to the sprint goal. By writing the goal prominently at the top of the planning document, teams ensure that every backlog item they pull serves that objective. This reframes the sprint from delivering points to delivering value, a principle reinforced in the Scrum Guide, which defines the sprint goal as “the single objective for the Sprint … providing flexibility in terms of the exact work needed to achieve it.”
Atlassian’s sprint planning guides support this. It states that sprint goals help reduce scope creep and keep everyone focused on outcomes rather than output. When you consistently frame sprints around goals instead of points, teams shift from chasing velocity to delivering business impact.
2. Run a Capacity Workshop Before Committing: Before commitments, run a collaborative session where you review historical velocity, subtract time off, and discuss unplanned-work trends. Export PTO calendars, meeting schedules, and previous sprint data. In that meeting, agree on buffers: hard buffer, 10% for critical issues and soft buffer, 5–10% for surprises.
Next, convert available hours to story points using your team's historical throughput (typically 0.2–0.3 points per productive hour). Then plan to commit only 85% of net capacity, a level associated with higher sprint success rates. Here's a quick product tour that shows you how to run a capacity planning workshop with Quely.
3. Track Flow Metrics, Not Just Velocity
Velocity alone rarely captures the health of delivery. To understand how work actually moves, track flow metrics like throughput, cycle time, WIP, and aging WIP. Each highlights different aspects of predictability and risk.
In addition to this, set WIP limits that are aligned with team size and adopt a “finish first” rule: once mid-sprint arrives, no new stories should be started until existing ones are complete. This prevents dilution of effort and reduces rollover.
Also, define the difference between good and bad carryover. Unfinished work that still advances the sprint goal can be acceptable. But spillover caused by poor slicing or overcommitment signals a problem with planning.
Flow metrics like cycle time and aging WIP are far stronger predictors of delivery risk than velocity. They help you manage flow, not just measure output, and give you the insight you need to improve predictability.
4. Make Scope Changes Transparent: Scope changes are sometimes necessary but hiding them inside burndown charts distorts reality. When new stories are added mid-sprint or existing ones are removed, record those changes explicitly instead of manipulating metrics to make the chart “look right.”
Create a clear record of what was added, removed, or re-estimated, and visualize this data in a simple bar or stacked chart. Each bar represents the total sprint scope, with color segments showing additions and removals over time. This makes trade-offs visible and helps stakeholders see that the team is adapting to change, not missing commitments.
For example, if three stories were added mid-sprint to address urgent production issues, record them separately. The burndown should reflect both the added scope and the completed work. A transparent visual tells a far truer story than a perfectly linear burndown that hides change.
This practice aligns with agile thought leaders like Atlassian advise you not to “fudge the numbers” on burndown charts or velocity reports, because transparency leads to better planning and trust. They define scope change as work added or removed after a sprint begins and recommend tracking it as a separate metric rather than hiding it in velocity.
Transparent scope tracking encourages healthier behavior: leaders see real trade-offs, your team learn to communicate change early, and sprints become more predictable. Instead of gaming the burndown, teams can use it as a tool for insight, not optics.
5. Add Mid-Sprint Confidence Checks: Midway through the sprint, take a short pause to gauge your team’s confidence in reaching the sprint goal. Ask each member to rate their confidence on a simple 1–5 scale, where 1 means “we’re at risk” and 5 means “on track.” Any score below 4 is a cue to talk. These quick conversations often surface the issues that derail your team later: hidden dependencies, blocked stories, or under-scoped work.
If confidence is low, treat it as an opportunity to adapt. Revisit scope, rebalance ownership, or escalate blockers early while there’s still time to course-correct. These mid-sprint check-ins promote continuous inspection and adaptation, two of Scrum’s core principles.
You can do all these async using Quely. You’ve already used it to plan your sprint and capacity. It now serves as a critical communication platform for all conversations related to the sprint.
6. Conduct Root-Cause Retrospectives: Retrospectives are far more valuable when they go beyond feelings and focus on facts. Before each session, send a short survey asking your team where time was lost during the sprint: through unexpected interruptions, unplanned work, or missed estimates.
During the retrospective, map these responses into categories such as bugs, meetings, scope churn, or support work. Visualizing capacity loss in this way helps you identify patterns instead of reacting to isolated complaints. Once those patterns are visible, assign different people on your team to fix them:
If bugs consumed most of the sprint, schedule stabilization time, or a rotating “bug sheriff.”
If meetings or support requests are overwhelming, limit attendees or rotate ownership.
If scope creep caused repeated spillovers, clarify how and when new work enters the sprint.
This approach changes retrospectives from vague post-mortems into audits that prevent overcommitment.
Atlassian’s Team Playbook recommends pre-retro surveys for this reason: they surface underlying issues early and make discussions more actionable.
Spotify takes this further through its Squad Health Check model, where teams rate key dimensions like delivery health, support burden, and process clarity. Over time, these visual “health snapshots” revealed chronic drains on capacity, such as ad-hoc requests consuming over 25% of development time. To address it, some squads introduced a rotating “support owner” role, which reduced context switching and improved predictability across sprints.
7. Treat Delays as Signals, Not Emergencies: When work slips, don’t just scramble to fix it. It’s also an opportunity to learn. Delays aren’t crises to mask or fix mid-sprint; they’re signals pointing to systemic issues in planning, estimation, or scope control.
Use your hard buffer (typically around 10%) only for production or customer incidents. All other unplanned work — last-minute requests, support tickets, or urgent testing should be tracked as its own metric. Over time, patterns in unplanned work reveal where processes or upstream dependencies need tightening.
If a sprint repeatedly suffers delays or spillover, increase the buffer slightly in the next iteration (15–20%) and observe whether predictability improves. Adjusting the buffer is a healthy response to reality, not an admission of failure. It’s how high-performing teams improve forecasting over time.
Just as importantly, resist the urge to re-estimate stories mid-sprint. Re-estimating distorts historical data and hides the true scope of slippage. Instead, carry unfinished work into the next sprint with its original estimate intact. This preserves the accuracy of your metrics and keeps learning loops honest.
When you treat delays as data for learning rather than emergencies, you build teams that improve predictability sprint by sprint, not by chasing perfect burndowns, but by continuously refining the system that produces them.
Tools That Improve Capacity Planning Accuracy & Prevent Sprint Overcommitment
To plan predictable sprints, you have to use tools that show how much capacity is available, where it’s being spent, and when it’s at risk. These platforms make it easier to plan realistically, spot bottlenecks early, and keep delivery predictable. Here are some of them:
Capacity-planning platforms: Sprint planning platforms like Quely and other Jira add-ons give your team the option to set their capacity. Some of them also pull in data from calendars, time-tracking systems, and past velocity to show how full the sprint is in real time.
When workloads exceed athresholds (for example, 80% capacity or 10% unplanned work), the system flags it before burnout or missed deadlines occur. Atlassian’s research shows that teams using structured capacity planning deliver up to 40% more story points and cut costs by as much as 30% due to smarter workload management. Here's how Quely's capacity planning feature helps you prevent overcommitment.
Flow metrics dashboards: These improve visibility. They track how work moves through the system, showing how much capacity is booked, how much unplanned work appears mid-sprint, and how confident the team can be in hitting its velocity target. Many dashboards send alerts when trends look risky, helping teams fix small issues before they turn into delays. This kind of visibility keeps leaders on track to deliver their sprint commitments and make better, faster decisions during the sprint.
AI-powered estimation tools: Tools like Quely offer product and engineering teams AI estimation. They analyze the work items, ask follow-up questions and use these answers to suggest more realistic story-point estimates.
By replacing gut feel with intelligent forecasting, these tools make estimation discussions more productive and help your team commit to work they can actually finish.
How to Handle Delays and Unexpected Work in Sprints
Even well-planned sprints still face delays. The culprits could be critical dependency slips, major bug, or an urgent support request. The difference between average and high-performing teams is how they plan for it. Here are some ways to hand these delays so you can remain on track to deliver your sprint commitments.
Preserve the hard buffer. Reserve around 10% of total capacity for emergencies such as production incidents or high-priority support requests. Avoid spending this buffer on scope creep or last-minute “nice-to-haves.” If unplanned work consistently exceeds 10%, treat it as a signal to inspect your processes rather than as a one-off interruption.
Track scope changes transparently. When work is added or removed mid-sprint, record it as its own metric rather than adjusting estimates or manipulating the burndown chart. This visibility helps stakeholders understand the trade-offs they’re making and discourages hidden scope creep.
Apply lessons learned. Use each retrospective to trace where time was lost whether from dependencies, unplanned work, or poor estimates. If certain tasks or teams repeatedly cause delays, negotiate earlier handoffs or add small contingency tasks to protect focus time. The goal isn’t to eliminate uncertainty but to reduce its impact through better planning.
Negotiate scope, not hours. When a major blocker appears, collaborate with the product owner to remove lower-value items or reduce scope while still protecting the sprint goal. It’s far better to adjust work than to overextend your team or compromise quality.
When you treat interruptions as data rather than disruptions, you help your team maintain momentum, make adjustments, and improve forecasting over time. The payoff is improved sprint delivery not because problems vanish, but because they’re anticipated and managed systematically.
Common Misconceptions That Lead to Overcommitment in Sprint Capacity Planning
Alot of times, the problems most teams face with sprint predictability does not come from poor execution. It’s from assumptions about capacity and commitment. Here are some of the most common misconceptions that contribute to overcommitment as well as what to do instead.
“Velocity is a promise.”
Velocity is not a commitment; it’s a rolling average of past throughput. Treating it as a promise turns what’s supposed to be a planning tool into a performance target. Use velocity as a forecast, then adjust it using capacity. It allows you to account for constraints like time off, meetings, and support work.
“We can make up time by working harder.”
Pushing your team to compensate for delays through overtime solves the problem temporarily. It hides deeper planning issues. Developers typically spend 40–50% of their time on non-coding tasks like testing, code reviews, and so on. Ignoring these realities leads to burnout and also makes your team skeptical of estimates. What drives delivery is sustainable pace, not heroic effort.
“Estimating in hours improves accuracy.”
Estimating in hours gives you the illusion of precision, but what it actually does is, it turns estimates into deadlines. That drives gaming behavior and anxiety instead of predictability. Flow metrics like cycle time and throughput offer a more objective view of how work actually moves and shows you where you can improve.
“We must finish everything in the sprint backlog.”
Your commitment is to the sprint goal, not the entire backlog. Allow for carryover when the unfinished work still contributes to that goal. Stop treating the backlog as an all-or-nothing commitment encourages overloading and discourages strategic trade-offs.
“More points equal more value.”
Story points measure effort and capacity, not business impact. Delivering more points doesn’t necessarily mean delivering more value. Measure success by customer outcomes, product quality, and learning velocity, not by story points.
The Bottom Line
Teams that plan capacity effectively deliver up to 40% more work per sprint and can reduce development costs by up to 30%. To stop overcommitting during sprint planning, anchor on sprint goals, run capacity workshops, use flow-based metrics, maintain buffers, and leverage capacity planning tools. The result is, you’d have more realistic commitments, reduced unplanned work, and improved predictability without burning out your team.
Frequently Asked Questions
What happens if an Agile team overcommits?
Overcommitment increases context switching, inflates work-in-progress, degrades quality, and drives burnout. Teams experience delivery delays, accumulate technical debt, and often game metrics to mask planning dysfunction.
How do you avoid overcommitting in sprint planning?
Run capacity workshops before committing, account for meetings and time off, maintain 10–15% capacity buffers, track flow metrics instead of just velocity, and commit to only 85% of net capacity.
What metrics should teams use instead of velocity?
Track throughput (items completed), cycle time, work-in-progress (WIP), and aging WIP. These flow metrics better reflect predictability and help teams identify bottlenecks earlier than velocity alone.
Next Steps: Avoid Sprint Overcommitments with Quely
Avoiding overcommitments in sprints starts with understanding your team’s capacity and ensuring every task is thoroughly analyzed and clearly defined. Quely provides key features to help Agile teams achieve this:
Accurate Task Estimation: Quely’s AI-powered estimation provides a detailed breakdown of tasks using the Fibonacci sequence. It factors in team members’ experience levels and allows them to estimate durations, ensuring your team sets realistic expectations for each sprint.
Capacity-Based Planning: Quely’s capacity planning feature shows each team member’s availability. As tasks are allocated, Quely provides real-time insights into who is overloaded and who has capacity, enabling you to balance workloads effectively.
Uncover Potential Risks: Quely’s autogenerated questions help teams uncover blind spots in their tasks. These AI-driven prompts lead to deeper discussions, helping identify risks or missing details early in the planning process.
By focusing on these critical features, Quely equips your team to plan smarter, avoid overloading members, and deliver on sprint goals with confidence. Implement Quely today to bring clarity and alignment to your sprint planning process.
Related posts






